스프링 핵심 기술의 응용
스프링의 모든 기술은 결국 객체지향적인 언어의 장점을 적극적으로 활용해서 코드를 작성하도록 도와주는 것이다. 이번에는 이 세 가지 기술을 애플리케이션 개발에 활용해서 새로운 기능을 만들어보고 이를 통해 스프링의 개발철학과 추구하는 가치, 스프링 사용자에게 요구되는 게 무엇인지 살펴보겠다.
SQL과 DAO의 분리
DB 테이블과 필드정보를 담고 잇는 SQL문장을 DAO에서 분리해야 한다. 왜냐하면 SQL의 변경 작업은 생각보다 빈번히 일어난다. 그때마다 DAO 코드를 수정하고 컴파일하는 작업은 번거롭고 실수하기 쉬워 위험하기 때문이다.
빈의 초기화 작업
빈의 제어권은 스프링에 있다. 빈 오브젝트를 생성하고 DI 작업을 수행해서 프로퍼티를 모두 주입해준 뒤에 미리 지정한 초기화 메소드를 호출해주는 기능을 갖고 있다.
빈 후처리기는 스프링 컨테이너가 빈을 생성한 뒤에 부가적인 작업을 수행할 수 있게 해주는 특별한 기능이다. 애노테이션을 이용한 빈 설정을 지원해주는 몇 가지 빈 후처리기가 있다.
@PostConstruct 는 java.lang.annotation 패키지에 포함된 표준 애노테이션이다. 스프링은 @PostConstruct 애노테이션을 빈 오브젝트의 초기화 메소드를 지정하는 데 사용한다.
변화를 위한 준비: 인터페이스 분리
특정 포맷의 파일과 특정 타입 컬랙션에 의존적이지 않아야 한다. 기술의 변화가 코드의 수정을 강제하지 말아야 한다. 변경되는 이유가 두 가지라면 단일 책임 원칙을 위반하는 셈이다. 그렇다고 한 가지 기술의 변화 때문에 새로운 클래스를 만들면 상당 부분의 코드가 중복되는 결과를 초래할 것이다.
SQL을 가져오는 것과 보관해두고 사용하는 것은 독자적인 이유로 변경 가능한 독립적인 전략이다. 서로 변하는 시기와 성질이 다른 것, 변하는 것과 변하지 않는 것을 함께 두는 건 바람직한 설계구조가 아니다. 서로 관심이 다른 코드들을 분리하고, 서로 코드에 영향을 주지 않으면서 유연하게 확장 가능하도록 DI를 적용해야 한다.
책임에 따른 인터페이스 정의
가장 먼저 할 일은 분리 가능한 관심사를 구분해보는 것이다. 독립적으로 변경 가능한 책임을 뽑아야 한다.
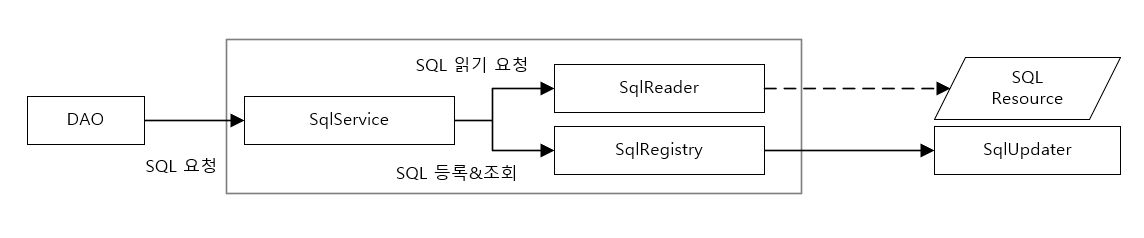
- SQL 정보를 외부의 리소스로부터 읽어오는 것이다. 리소스는 단순한 텍스트, XML, 엑셀, DB일 수도 있다. SQL이 담겨 있는 리소스가 어떤 것이든 상관없이 애플리케이션에서 활용 가능하도록 메모리에 읽어들이는 것을 하나의 책임으로 생각해볼 수 있다.
- 읽어온 SQL을 보관해두고 있다가 필요할 때 제공해주는 것이다. SQL의 양에 따라 다양한 방식의 저장 방법을 생각해볼 수 있다.
- 서비스를 위해서 한 번 가져온 SQL을 필요에 따라 수정할 수 있게 하는 것이다. 시스템 운영 중에 서버를 재시작하거나 애플리케이션을 재설치하지 않고도 SQL을 긴급히 변경해야하 하는 경우가 있다. 이를 위해 사용 중인 SQL을 수정하는 기능도 생각할 수 있다.
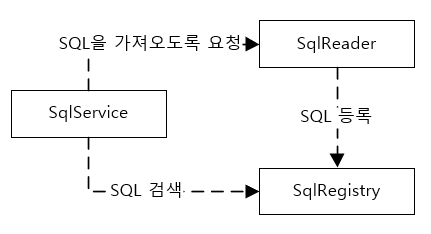
- SqlReader는 내부에 갖고 있는 SQL 정보를 형식에 맞춰서 돌려주는 대신, 협력관계에 있는 의존 오브젝트인 SqlRegistry에게 필요에 따라 등록을 요청할 때만 활용하면 된다. SqlReader가 SqlRegister와 의존관계를 가지고 작업을 진행해야 한다. SqlReader가 사용할 SqlRegister는 SqlService가 제공해 준다.
SqlRegistry 인터페이스
package springbook.user.sqlservice;
public interface SqlRegistry {
void registrySql(String key, String sql);
String findSql(String key) throws SqlNotFoundException;
}
SQL을 등록하고 검색하는 두 가지 기능을 메소드로 정의한다. 검색의 경우 실패할 때는 예외를 던지게 한다. 이 예외는 복구할 가능성이 적어 런타임 예외로 한다. 하지만 레지스트리가 여러개라면 한 레지스트리에서 검색이 실패하면 다른 레지스트리에서 검색할 수 있다. 따라서 복구할 여지가 있으므로 런타임 예외지만 명시적으로 메소드가 던지는 예외를 선언해두는 편이 좋다.
SqlReader 인터페이스
public interface SqlReader {
void read(SqlRegistry sqlRegistry);
}
SqlReader는 SqlRegistry오브젝트를 메소드 파라미터로 DI 받아서 읽어들인 SQL을 등록하는 데 사용하도록 만들어어야 한다.
read메소드는 SQL을 외부에서 가져와 SqlRegistry에 등록한다. 다양한 예외가 발생할 수 있겠지만 대부분 복구 불가능한 예외이므로 굳이 예외를 선언해두지 않았다.
자기참조 빈으로 시작하기
다중 인터페이스 구현과 간접 참조
인터페이스는 구현의 개념이지만 일종의 상속의 개념으로 생각할 수 있다. 인터페이스의 구현은 타입을 상속하는 것이다. 같은 타입으로 존재하지만 다른 구현을 가진 오브젝트를 만들 수 있다는 다형성을 활용할 수 있다.
조금 이상하지만 모든 기능을 구현하고 관심사가 분리되지 않은 클래스를 인터페이스를 하나하나 구현하면서 분리할 수 있다.
디폴트 의존관계
외부에서 DI 받지 않는 경우 기본적으로 자동 적용되는 의존관계를 말한다.
package springbook.user.sqlservice;
public class DefaultSqlService extends BaseSqlService {
public DefaultSqlService() {
setSqlReader(new JaxbXmlSqlReader());
setSqlRegistry(new HasMapSqlRegistry());
}
}
DI 설정이 없는 경우 디폴트로 적용하고 싶은 의존 오브젝트를 생성자에서 넣어준다. DI란 클라이언트 외부에서 의존 오브젝트를 주입해주는 것이지만 이렇게 자신이 사용할 디폴트 의존 오브젝트를 스스로 DI하는 방법도 있다.
JaxbXmlSqlReader의 sqlmapFile프로퍼티를 채워주어야 한다. 이를 위해 DefaultSqlService의 프로퍼티로 정의할 수도 있지만 JaxbXmlSqlReader는 디폴트 의존 오브젝트이기에 적절하지 않다. 디폴트라는 건 다른 명시가 없는 경우 기본적으로 사용하겠다는 의미다. 반드시 필요하지도 않은 sqlmapFile 프로퍼티를 DefaultSqlService가 프로퍼티로 등록하는 건 바람직하지 않다.
JaxbXmlSqlReader의 sqlmapFile 프로퍼티가 기본적으로 사용될 만한 디폴트 값을 가질 수 있다. 관례적으로 사용할 만한 이름을을 정해 디폴트로 넣어주면 된다.
public class JaxbXmlSqlReader implements SqlReader {
private static final String DEFAULT_SQLMAP_FILE = "sqlmap.xml";
private String sqlmapFile = DEFAULT_SQLMAP_FILE;
public void setSqlmapfile(String sqlmapFile) {this.sqlmafile = sqlmapFile;}
디폴트로 만드는 오브젝트가 매우 복잡하고 많은 리소스를 소모한다면 디폴트 의존 오브젝트가 아예 만들어지지 않게 하는 방법을 써야 한다. 예를 들어 @PostConstruct 초기화 메소드를 이용해 프로퍼티가 설정됬는지 확인하고 없는 경우에만 디폴트 오브젝트를 만드는 방법을 사용한다.
리소스 로더
스프링에는 URL클래스와 유사하게 접두어를 이용해 Resource 오브젝트를 선언하는 방법이 있다. 문자열 안에 리소스의 종류와 위치를 함게 표현하게 해주는 것이다. 그리고 이렇게 문자열로 정의된 리소스를 실제 Resource 타입 오브젝트로 변환해주는 ResourceLoader를 제공한다. ResourceLoader의 구현은 다양할 수 있으므로 인터페이스로 정의되어 있다.
package org.springframework.core.io;
public interface ResourceLoader {
Resource getResource(String location);
}
접두어가 없는 경우 ResourceLoader 구현에 따라 리소스의 위치가 결정된다.
ResourceLoader의 대표적인 예는 스프링의 애플리케이션 컨택스트다. 애플리케이션 컨텍스트가 구현해야 하는 인터페이스인 ApplicationContext는 ResourceLoader를 상속하고 있다. 따라서 모든 애플리케이션 컨텍스트는 리소스 로더이기도 한다.
스프링 컨테이너는 리소스 로더를 다양한 목적으로 사용한다.
- 스프링 설정 정보가 담긴 XML 파일도 리소스 로더를 이용해 Resource형태로 읽어온다.
- 외부에서 읽어오는 모든 정보는 리소스 로더를 사용한다.
- 빈의 프로퍼티 값을 변환할 때도 리소스 로더가 자주 사용된다.
- 스프링이 제공하는 빈으로 등록 가능한 클래스에 파일을 지정해주는 프로퍼티는 대부분 리소스 타입.
인터페이스 상속을 통한 안전한 기능확장
DI와 기능의 확장
DI의 가치를 제대로 얻으려면 DI에 적합한 오브젝트 설계가 필요하다
DI를 의식하는 설계
모든 기능을 클래스 하나 안에 마구 섞어 구현하지 않는다. 내부 기능을 적절한 책임과 역할에 따라 분리하고, 인터페이스를 정의해 느슨하게 연결해주고, DI를 통해 유여한하게 의존관계를 지정하도록 설계해야 한다. DI로 인해 오브젝트들이 서로 세부적인 구현에 얽매이지 않고 유연한 방식으로 의존관계를 맺으며 독립적으로 발전할 수 있다.
DI를 적용하려면 최소한 두 개 이상의, 의존관계를 가지고 서로 협력해서 일하는 오브젝트가 필요하다. 적절한 책임에 따라 오브젝트를 분리해줘야 한다. 그리고 항상 의존 오브젝트는 자유롭게 확장될 수 있다는 점을 염두에 둬야 한다. DI는 런타임 시에 의존 오브젝트를 다이내믹하게 연결해줘서 유연하게 확장하는 것이 목적이기 때문에 항상 확장을 염두해 오브젝트 관계를 생각해야 한다.
확장은 항상 미래에 일어나는 일이다. DI는 확장을 위해 필요한 것이므로 항상 미래에 일어날 변화를 예상하고 고민해야 적합한 설계가 가능하다.
DI 인터페이스 프로그래밍
인터페이스를 사용하는 첫 번째 이유는 다형성을 얻기 위해서다. 하나의 인터페이스를 통해 여러 개의 구현을 바꿔가면서 사용할 수 있게 하는 것이 DI가 추구하는 첫 번째 목적이다. 하지만 다형성을 편리하게 적용하는 것 때문이라면 클래스 상속을 통해서라도 구현을 확장할 수 있다.
인터페이스를 사용하는 또 다른 이유는 인터페이스 분리 원칙을 통해 클라이언트와 의존 오브젝트 사이의 관계를 명확하게 해줄 수 있기 때문이다. A와 B가 인터페이스로 연결되어 있다는 의미는 다르게 해석하면 A가 B를 바라볼 때 해당 인터페이스라는 창을 통해서 본다는 뜻이다. 따라서 이 인터펭시를 구현한 오브젝트라면 DI가 가능하다.
하나 이상의 인터페이스를 구현한 클래스도 사용할 수 있다. 2개 이상의 다른 인터페이스를 구현하는 이유는 그 오브젝트를 다른 인터페이스를 통해 이용하는 다른 클라이언트가 존재하기 때문이다. 즉 인터페이스는 하나의 오브젝트가 여러 개를 구현할 수 있으므로, 하나의 오브젝트를 바라보는 창이 여러 가지일 수 있다는 뜻이다. 각기 다른 관심과 목적을 가지고 어떤 오브젝트에 의존하고 있을 수 있다는 의미다.
오브젝트가 그 자체로 충분히 응집도가 높은 작은 단위로 설계됐더라도, 목적과 관심이 각기 다른 클라이언트가 있다면 인터페이스를 통해 이를 적절하게 분리해줄 필요가 있고, 이를 객체지향 설계 원칙에서는 인터페이스 분리 원칙(Interface Segregation Principle)이라고 부른다.
인터페이스를 사용하지 않고 직접 클래스를 참조하는 방식으로 DI하면 인터페이스 분리 원칙과 같은 클라이언트에 특화된 의존관계를 만들어낼 방법 자체가 없는 것이다.
인터페이스 상속
하나의 오브젝트가 구현하는 인터페이스를 여러 개 만들어서 구분하는 이유 중의 하나는 오브젝트의 기능이 발전하는 과정에서 다른 종류의 클라이언트가 등장하기 때문이다. 때로는 인터페이스를 여러개 만드는 대신 기존 인터페이스를 상속을 통해 확장하는 방법도 사용된다.
인터페이스 분리 원칙의 장점은 모든 클라이언트가 자신의 관점에 따른 접근 방식을 간섭 없이 유지할 수 있다는 점이다. 기존 클라이언트에는 영향을 주지 않은 채로 오브젝트의 기능을 확장하거나 수정할 수 있다.
스프링 3.1의 DI
객체지향적인 코드의 장점인 유연성과 확장성을 스프링 스스로가 충실하게 지켜왔음.
스프링 프레임워크 자체도 DI 원칙을 충실하게 따라서 만들어졌기 때문에 기존 설계와 코드에 영향을 주지 않고도 꾸준히 새로운 기능을 추가하고 확장할 수 있다.
자바 언어의 변화와 스프링
DI의 원리는 변하지 않았지만 DI가 적용하는 자바 언어에는 많은 변화가 있었다. 이러한 변화는 DI 프레임워크인 스프링의 사용 방식에 여러 영향을 주었다.
애노테이션의 메타정보 활용
애노테이션이 등장함에 따라 자바 코드의 메타정보를 데이터로 활용하는 프로그래밍 방식이 확산된다. 애노테이션은 옵션에 따라 컴파일된 클래스에 존재하거나 애플리케이션이 동작할 때 메모리에 로딩됙도 하지만 자바 코드가 실행되는 데 직접 참여하지 못한다. 리플렉션 API를 이용해 애노테이션의 메타정보를 조회하고, 애노테이션 내에 설정된 값을 가져와 참고하는 방법이 전부다.
애노테이션 자체는 클래스의 타입에 영향을 주지도 못하고, 일반 코드에서 활용되지 못하기 때문에 객체지향 프로그래밍 스타일의 코드나 패턴 등에 적용할 수 없다.
애노테이션은 애플리케이션의 핵심 로직을 담은 자바 코드와 이를 지원하는 IoC 방식의 프레임워크, 그리고 프레임워크가 참조하는 메타정보라는 세 가지로 구성하는 방식이 잘 어울리기 때문이다.
애노테이션이 부여된 클래스의 패키지, 클래스 이름, 접근 제한자, 상속한 클래스나 구현 인터페이스가 무엇인지 알 수 있다. 클래스의 필드나 메소드 구성도 확인할 수 있다. 단순한 애노테이션 하나를 자바 코드에 넣는 것만으로도, 애노테이션을 참고하는 코드에서는 많은 부가정보를 얻어낼 수 있다.
정책과 관례를 이용한 프로그래밍
애노테이션 같은 메타정보를 활용하는 프로그래밍 방식은 코드를 이용해 명시적으로 동작 내용을 기술하는 대신 코드 없이도 미리 약속한 규칙 또는 관례를 따라서 프로그램이 동작하도록 만드는 프로그래밍 스타일을 적극적으로 포용하게 만들었다.
미리 정의한 규칙에 따라서 프레임워크가 작업을 수행한다. 이러한 스타일의 프로그래밍 방식은 자바 코드로 모든 과정을 직접 표현했을 때에 비해서 작성해야 할 내용이 줄어든다는 장점이 있다. 자주 반복되는 부분을 관례화하면 더 많은 내용을 생략할 수 있다.
반면에 프로그래밍 언어나 API 사용법 외에 미리 정의된 규칙과 관례를 기억해야 하고, 메타정보를 보고 프로그램이 어떻게 동작할지 이해해야 하는 부담을 주기도 한다. 익숙해지면 편리해지지만, 그때까지 적지 않은 학습 비용이 들고, 자칫 잘못 이해하고 있을 경우 찾기 힘든 버그를 만들기도 한다.
제대로 활용하려면 관례화된 정책을 기억하고 코드를 작성해야할 수 있다. 정책을 기억하지 못하거나 잘못 알고 있을 경우 의도한 대로 동작하지 않는 코드가 만들어질 수 있다.
@Autowired VS @Resource
Resource는 Autowired와 유사하게 필드에 빈을 주입받을 때 사용한다. @Autowired는 필드의 타입을 기준으로 빈을 찾고 @Resource는 필드 이름을 기준으로 한다는 점이다.
수정자 메소드
Autowired를 빈의 필드에 붙이는 경우 수정자 메소드를 거치지 않고 Java Reflection을 통해 제약조건을 우회해서 직접 값을 넣어 준다. 하지만 스프링 컨테이너에서 의존관계를 맺어주는 경우에는 상관없지만 수정자 메소드를 꼭 사용해야하는 경우가 있다.
- 수정자 메소드가 주어진 오브젝트를 그대로 필드에 저장하지 않고 오브젝트를 customizing한 뒤 저장해야하는 경우
- 스프링과 무관한 순수한 단위 테스트를 만드는 경우, 테스트를 위한 목 오브젝트가 수정자 메소드를 통해 주입할 수 있게 해준다.
무조건 수정자 메소드를 삭제하면 안된다는 것은 아니다. 목 오브젝트를 사용해 테스트를 만들기가 어려운 경우 스프링 컨테이너 안에서 DI가 이뤄진 뒤에 테스트를 수행하는 것이 옳다. 필요없는 수정자 메소드는 지우도록 하자.
비즈니스 로직을 갖고 있어서 목 오브젝트를 적절히 활용해 빠르게 동작하는 단위 테스트를 만들 수 있는 경우에는 수정자 메소드를 남겨두는 편이 좋다.
@Component
이 애노테이션은 클래스에 부여된다. 클래스는 빈 스캐너를 통해 자동으로 빈으로 등록된다.
정확히 @Component 또는 @Component를 메터 애노테이션으로 갖고 있는 애노테이션이 붙은 클래스가 자동으로 빈 등록 대상이 된다. @Component 애노테이션은 빈으로 등록될 후보 클래스에 붙여주는 일종의 마커라고 보면 된다.
스프링 컨테이너에 등록된 빈을 가져와 사용할 때는 @Autowired를 통해 가져오면 된다. 심지어 같은 클래스 안에 @Bean 메소드가 존재하는 경우에도 메소드 호출대신 @Autowired를 통해 빈을 참조할 수 있다.
Component 애노테이션이 달린 클래스를 자동으로 찾아서 빈을 등록해주게 하려면 빈 스캔 기능을 사용하겠다는 애노테이션 정의가 필요하다. 빈 자동등록은 컨테이너가 디폴트로 제공하는 기능이 아니다. 프로젝트 내의 모든 클래스패스를 뒤져가며 애노테이션이 달린 클래스를 찾는 것은 비용이 많이 들기 때문이다. 그렇기 때문에 특정 패키지 아래서만 찾도록 기준이 되는 패키지를 지정해줄 필요가 있다.
이 때 사용하는 애노테이션은 @ComponentScan애노테이션이다. DI 설정 클래스에 붙여주면 된다.
출처
토비의 스프링(책)
댓글남기기