Java HashMap 동작원리
들어가기 전에
- Java 버전 7 ~ 8을 기준으로 작성합니다.
- HashMap 자체의 소스 코드는 OracleJDK와 OpenJDK나 같습니다.
HashMap과 HashTable
HashMap과 HashTable은 Java API의 이름이다.
| HashTable | HashMap | |
|---|---|---|
| 등장시기 | JDK 1.0 | Java 2 |
| Map 인터페이스 구현 | 예 | 예 |
| 보조 해시 함수 (해시 충돌 가능성 낮춰 성능을 높임) |
없음 | 있음 |
| 지속적인 개선 | 아니요 | 예 |
- HashMap, HashTable의 정의 : 키에 대한 해시 값을 사용하여 값을 저장하고 조회하며, 키-값 쌍의 개수에 따라 동적으로 크기가 증가하는 associate array
- Associate array(연관 배열) : Map, Dicitionary, Symbol Table
해시 분포와 해시 충돌
- 동일하지 않은 어떤 객체 X, Y 에 대하여
X.equals(Y)이 거짓일 때,X.hashCode() != Y.hashCode()가 같지 않으면 완전한 해시 함수(perfect hash functions)라 부른다. - Boolean같이 서로 구별되는 객체의 종류가 적거나, Primitive type(기본형 타입)의 Wrapper 객체는 객체가 나타내는 값 자체를 해시 값으로 사용할 수 있다. 따라서 완전한 해시 함수 대상으로 삼을 수 있다.
- String이나 POJO에 대하여 완전한 해시 함수를 제작하는 것은 불가능 하다.
- HashMap은 기본적으로 각 객체의 hashCode() 메서드가 반환하는 int형을 사용한다.
- 논리적으로 생성가능한 객체의 수가 2^32보다 많을 수 있기 때문에 완전한 자료 해시 함수를 만들 수 없다.
- 메모리를 절약하기 위해 실제 해시 함수의 정수 표현 범위(N)보다 작은 M개의 원속 있는 배열을 사용한다. 그래서 해시 코드에 대한 나머지 값을 해시 버킷 인덱스 값으로 사용한다.
int index = X.hashCode() % M; - 해시 버킷(size : M)을 사용하면 서로 다른 해시 코드 값을 갖는 서로 다른 객체가 1/M의 확률로 같은 해시 버킷을 사용하게 된다. 이는 해시 함수가 얼마나 해시 충돌을 회피하도록 잘 구현했느냐에 상관없이 발생할 수 있는 또 다른 종류의 해시 충돌이다.
해시 충돌 해결
- 충돌을 막기 위해 Open Addressing, Separate Chaining 두 가지 방법으로 충돌의 회피한다.
- 이 둘 외에도 충돌을 해결하기 위한 다양한 자료 구조가 있지만, 거의 모두 이 둘을 응용한 것이다.
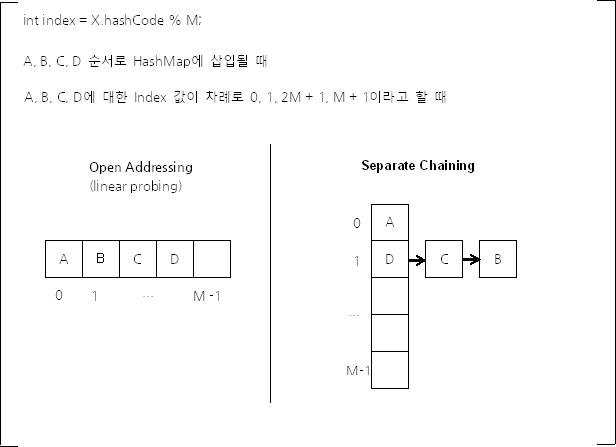
Open Addressing
데이터를 삽입하려는 해시 버킷이 이미 사용 중인 경우 다른 해시 버킷에 해당 데이터를 삽입하는 방식이다. 데이터를 저장/조회할 해시 버킷을 찾을 때에는 Linear Probing, Quadratic Probing 등의 방법을 사용한다.
- 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비하여 캐시 효율이 높다.
- 적은 데이터에서는 Separate Chaining보다 성능이 더 좋다.
- M값(배열의 크기)이 커질수록 캐시 효율이라는 Open Addressing의 장점은 사라진다. 배열의 크기가 커지면, L1, L2 캐시의 적중률이 낮아지기 때문이다.
Separate Chaining
각 배열의 인자는 인덱스가 같은 해시 버킷을 연결한 링크드 리스트의 첫 부분(head)이다.
- Java HashMap에서 사용하는 방식이다.
- Open Addressing에 비해 데이터의 삭제를 효율적으로 처리할 수 있다.
- 많은 데이터에서 Open Addressing 보다 빠르다.
- 충돌이 잘 발생하지 않도록 ‘조정’할 수 있다면 Worst Case에 가까운 일이 발생하는 것을 줄일 수 있다.(보조 해시 함수)
Java 8 HashMap의 Node 클래스
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
// 클래스 이름은 다르지만, Java 7의 Entry 클래스와 구현 내용은 같다.
}
// LinkedHashMap.Entry는 HashMap.Node를 상속한 클래스다.
// 따라서 TreeNode 객체를 table 배열에 저장할 수 있다.
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
// Red Black Tree에서 노드는 Red이거나 Black이다.
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
final TreeNode<K,V> root() {
// Tree 노드의 root를 반환한다.
}
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
// 해시 버킷에 트리를 저장할 때에는, root 노드에 가장 먼저 접근해야 한다.
}
// 순회하며 트리 노드 조회
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {}
final TreeNode<K,V> getTreeNode(int h, Object k) {}
static int tieBreakOrder(Object a, Object b) {
// TreeNode에서 어떤 두 키의comparator 값이 같다면 서로 동등하게 취급된다.
// 그런데 어떤 두 개의 키의 hash 값이 서로 같아도 이 둘은 서로 동등하지
// 않을 수 있다. 따라서 어떤 두 개의 키에 대한 해시 함수 값이 같을 경우,
// 임의로 대소 관계를 지정할 필요가 있는 경우가 있다.
}
final void treeify(Node<K,V>[] tab) {
// 링크드 리스트를 트리로 변환한다.
}
final Node<K,V> untreeify(HashMap<K,V> map) {
// 트리를 링크드 리스트로 변환한다.
}
// 다음 두 개 메서드의 역할은 메서드 이름만 읽어도 알 수 있다.
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {}
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {}
// Red Black 구성 규칙에 따라 균형을 유지하기 위한 것이다.
final void split (…)
static <K,V> TreeNode<K,V> rotateLeft(…)
static <K,V> TreeNode<K,V> rotateRight(…)
static <K,V> TreeNode<K,V> balanceInsertion(…)
static <K,V> TreeNode<K,V> balanceDeletion(…)
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
// Tree가 규칙에 맞게 잘 생성된 것인지 판단하는 메서드다.
}
}
공통점
- WorstCase O(M) 이다.
- Separate Chaining
HashMap에서의 Separte Chaining
자바의 7과 8의 버전별로 Separate Chaining에 대한 구현은 서로 다르다.
| 자바 7 | 자바 8 | |
|---|---|---|
| get() 기대값 | E(N/M) | E(log(N/M)) |
| 버킷 자료 구조 | 링크드 리스트 | 적은 갯수(한계점 6) : 링크드 리스트 많은 갯수(한계점 8) : 트리 |
| 버킷 원소 타입 | Entry 클래스 | Node 클래스 (Entry를 Implement함, 하위 클래스 TreeNode가 있다, Red-Black Tree를 이용한다.) |
해시 버킷 동적 확장
해시 버킷의 개수가 적다면 메모리 사용을 아낄 수 있지만 해시 충돌로 인해 성능상 손실이 발생한다.
→ HashMap은 키-값 쌍 데이터 개수가 일정 개수 이상이 되면, 해시 버킷의 개수를 두 배로 늘린다.
- 해시 버킷 개수의 기본값 : 16
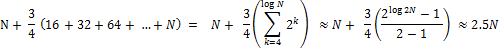
- 기본 생성자로 생성한 HashMap을 이용하여 많은 양의 데이터를 삽입할 때에는, 최적의 해시 버킷 개수를 지정한 것보다 약 2.5배 많이 키-값 쌍 데이터에 접근해야 한다.
- 문제점 : 해시 버킷의 개수 M이 2^a형태가 되어 index = X.hashCode() % M을 계산할 때 X.hashCode()의 하위 a개의 비트만 사용하게 된다. 해시 함수가 32비트 영역을 고르게 사용하도록 만들어도 해시 값을 2의 승수로 나누면 해시 충돌이 쉽게 발생한다.
보조 해시 함수
index = X.hashCode() % M을 계산할 때 사용하는 M 값은 소수일 때 index 값 분포가 가장 균등할 수 있다. 그러나 M은 소수가 아니기 때문에 별도의 보조 해시 함수를 이용해여 index값 분포가 가급적 균등할 수 있도록 해야 한다.
보조 해시 함수(supplement hash function)의 목적은 ‘키’의 해시 값을 변형하여, 해시 충돌 가능성을 줄이는 것이다.
Java 7
final int hash(Object k) {
// Java 7부터는 JRE를 실행할 때, 데이터 개수가 일정 이상이면
// String 객체에 대해서 JVM에서 제공하는 별도의 옵션으로
// 해시 함수를 사용하도록 할 수 있다.
// 만약 이 옵션을 사용하지 않으면 hashSeed의 값은 0이다.
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// 해시 버킷의 개수가 2a이기 때문에 해시 값의 a비트 값만을
// 해시 버킷의 인덱스로 사용한다. 따라서 상위 비트의 값이
// 해시 버킷의 인덱스 값을 결정할 때 반영될 수 있도록
// shift 연산과 XOR 연산을 사용하여, 원래의 해시 값이 a비트 내에서
// 최대한 값이 겹치지 않고 구별되게 한다.
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Java 8
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
댓글남기기